







如何获得基因序列?——在NCBI中查找目的基因实例
基因,即具有遗传效应的DNA片段,是控制生物性状的基本遗传单位。基因有两个特点,一是能忠实地复制自己,以保持生物的基本特征;二是基因能够“突变”,突变绝大多数会导致疾病,因此研究某种疾病的病理要从基因开始,研究基因当然就要知道该基因序列了,如何查找基因就是关键问题了,这里,我们将举例详细讲解一下如何查找基因。
1. 首先可以根据文献获得目的基因序列
通过阅读文献,找到你感兴趣的基因,根据文中提到的该基因在NCBI中的ID号,直接打开http://www.ncbi.nlm.nih.gov , 在All Databases后的下拉框中选择Nucleotide,把基因 ID号输入Search前面的文本框中,点“Search”,就可以找到该基因了。
举例说明,例如:在2003年JBC的文章(Conditional Knock-out of Integrin-linked Kinase Demonstrates an Essential Role in Protein Kinase B/Akt Activation)中出现了“calreticulin (GenBank accession number gi 16151096)”,那么把“16151096”输入Search前面的文本框中,点“Search”,就可以找到该基因了(当然包括基因序列等相关信息),见下图。

检索结果界面如下图,可以看到GenBank号为AY047586的CALR基因的相关信息了。
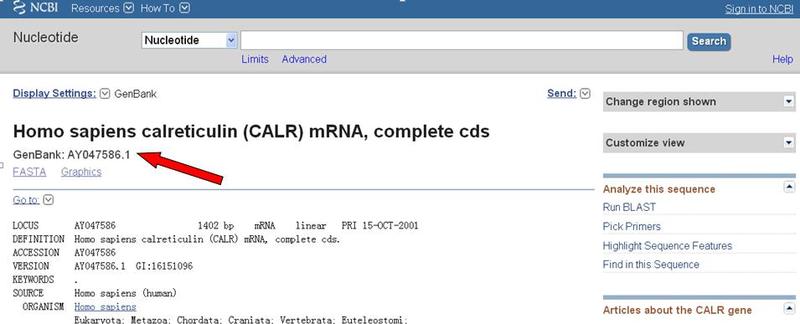
里面有很多基因的信息,再往下是基因的的核酸序列(ORIGIN之后)。

基因的翻译区(CDS)点击 CDS即可得到。
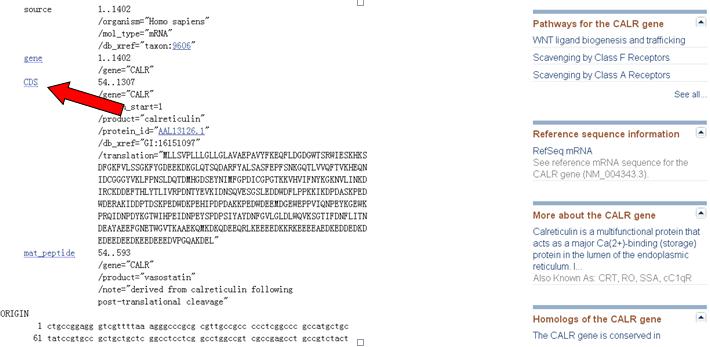
下图标示的褐色区域序列即为基因的编码区序列。

这里需要指出一下,在显示基因的页面右下侧有一个LinkOut to external resource,里面是与该基因相关的链接,对于该基因的相关研究是很有用的。

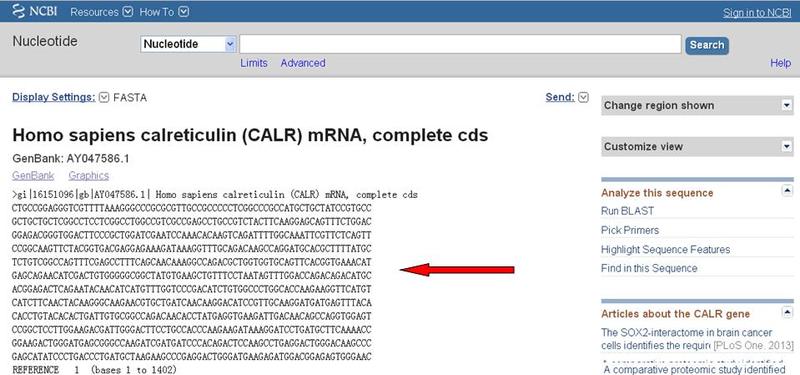
如果你只想获得序列(例如去设计PCR引物的时候),那就可以选择FASTA,这样就得到了FASTA格式的序列文件,没有其他数字和格式的干扰。
这就是FASTA格式的序列:
2. 根据已经获得的基因的相关信息进行查找
如果只是知道基因的名字,怎么查序列呢?还是举例说明,比如研究的基因名称是人的VEGF基因,那么怎么在NCBI中找到它呢?首先打开http://www.ncbi.nlm.nih.gov/
在All Databases的下拉框中选择Gene,然后在中间的文本框中输入基因名称“VEGF”,点击Search...
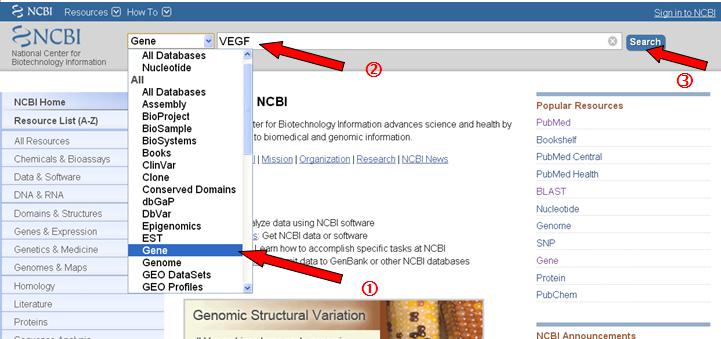
搜索结果如下:
结果有很条,哪一条是我想要的基因呢?这时候要根据自己研究的基因所属物种来选择,如研究的是人属(Homo sapiens)的,则点击第四条,出现如下界面。
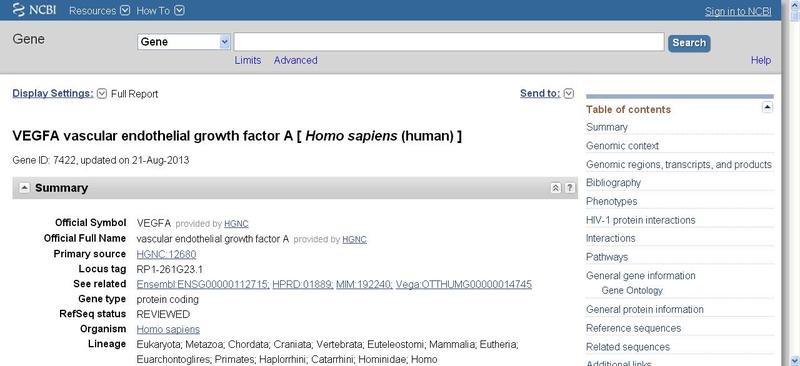
里面是这个基因的详细信息,需要指出的是,在NCBI中,基因有很多别名(Aliases),你得到的基因名和NCBI中记录的名称有可能不一致。比如在这里,VEGFA是NCBI中记录的基因名称,而它还有很多别名,比如VPF, VEGF(这就是我们要找的基因名称 ), MVCD1。
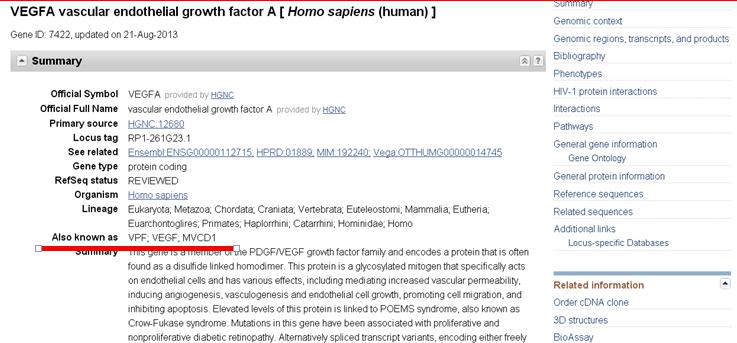
再往下看,可以看到里面可以看到该基因再染色体上的位置,以及基因在转录时有几个剪切体等信息。
这个基因有很多转录本(isoform a 到 isoform r),可以看到其的mRNA的链接(如NM_001025366.2)和蛋白质的链接(如NP_001020537.2 )

isoform a 到 isoform r哪个是自己想找的基因呢?这就需要根据自己查阅的文献以及在这些基因序列后面的解释来确定了。客户提供基因的ID号更好,如果不提供,那么我们一般选择众多mRNA转录本中最长的转录本(longest isoform),即下图中所标示的isoform a 。
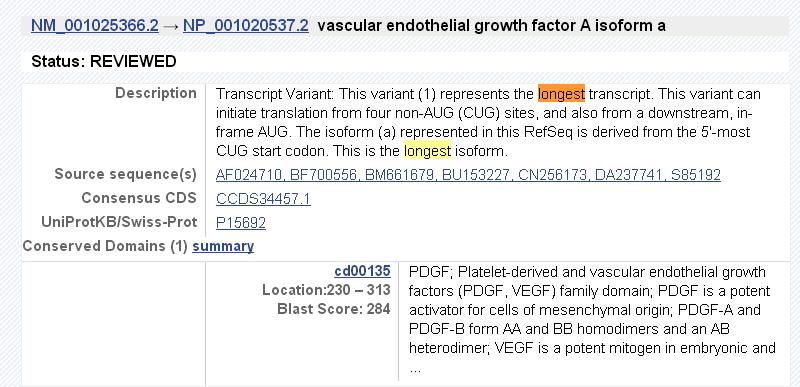
如果要找的基因是第一个序列即isoform a, 就可以点击NM_001025366.1,得到如下基因的信息界面:

点击NP_001020537.2 就可以获得该转录本基因翻译的蛋白信息。

- 浏览 21836 次

